Генератор robots.txt
Соберите корректный файл robots.txt, чтобы задать краулерам Google, Bing и других систем, какие разделы сайта можно обходить и индексировать.
Настройки и результат
Правила обхода (User-agent: *)
Сгенерированный robots.txt
User-agent: * Allow: /
Частые примеры robots.txt
Готовые конфигурации под типичные задачи — можно скопировать и адаптировать под свой домен.
Разрешить всё (по умолчанию)
Открыто для всех ботов. Типичный вариант для публичных сайтов.
User-agent: * Allow: /
Закрыть админку и личные разделы
Публичный контент в обходе, служебные пути под запретом.
User-agent: * Disallow: /admin Disallow: /wp-admin Disallow: /private Sitemap: https://example.com/sitemap.xml
Блокировать обучающих ИИ-ботов
Поисковые боты ходят как обычно, обучение моделей — по отдельным user-agent.
User-agent: * Allow: / User-agent: GPTBot Disallow: / User-agent: ClaudeBot Disallow: / User-agent: Google-Extended Disallow: / User-agent: PerplexityBot Disallow: / User-agent: Bytespider Disallow: / User-agent: CCBot Disallow: /
Закрыть сайт от всех ботов
Полностью приватный сайт — без обхода роботами.
User-agent: * Disallow: /
Что такое файл robots.txt?
Файл robots.txt — простой текст в корне сайта по адресу ваш-домен.ru/robots.txt, в котором вы сообщаете ботам, какие URL можно обходить, а какие нет. Это общепринятый протокол (Robots Exclusion Protocol), который учитывают Google, Bing и другие системы.
robots.txt не заменяет безопасность: умышленный обход возможен. Но для технического SEO файл важен: так вы не расходуете краулинг на админку, дубли и служебные страницы и направляете поиск на полезный контент.
- Закрывайте служебные разделы. Disallow для путей вроде /admin, /wp-admin, /dashboard снижает попадание бэкенда в выдачу и лишний обход.
- Укажите sitemap. Строка Sitemap: помогает ботам быстрее найти карту сайта без ручной подачи только через кабинеты.
- Не блокируйте CSS и JS. Google рендерит страницу через стили и скрипты; их запрет может ухудшить понимание сайта и индексирование.
- Проверяйте перед публикацией. В Google Search Console есть тестер robots.txt — ошибка может закрыть весь сайт от обхода.
Частые вопросы
Коротко о robots.txt и директивах для краулеров.
Связанные инструменты
Другие бесплатные утилиты из каталога.
Генератор URL slug
Заголовок или фраза в чистый SEO-friendly slug: нижний регистр и дефисы.
Чек-лист SEO
Техника, on-page, контент и ссылки — по шагам без пропусков.
Предпросмотр сниппета
Как title и description выглядят в выдаче Google до публикации.
Генератор meta-тегов
HTML: title, description, Open Graph и Twitter Card для страницы.

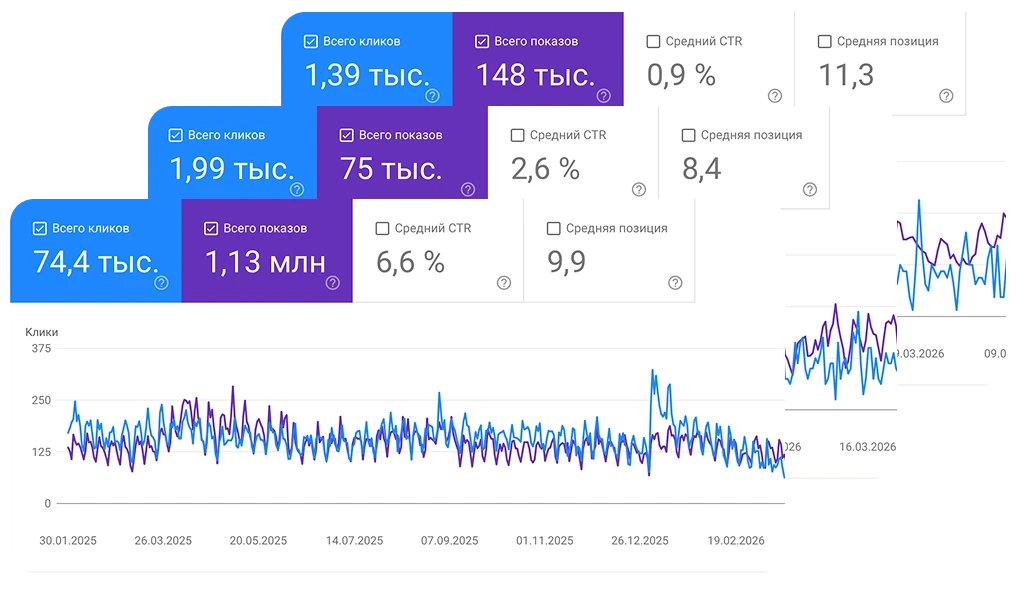
SEO на автопилоте.
Соберите весь SEO-процесс в одном окне — исследование тем, тексты, публикация и аналитика без переключения между сервисами.
Начать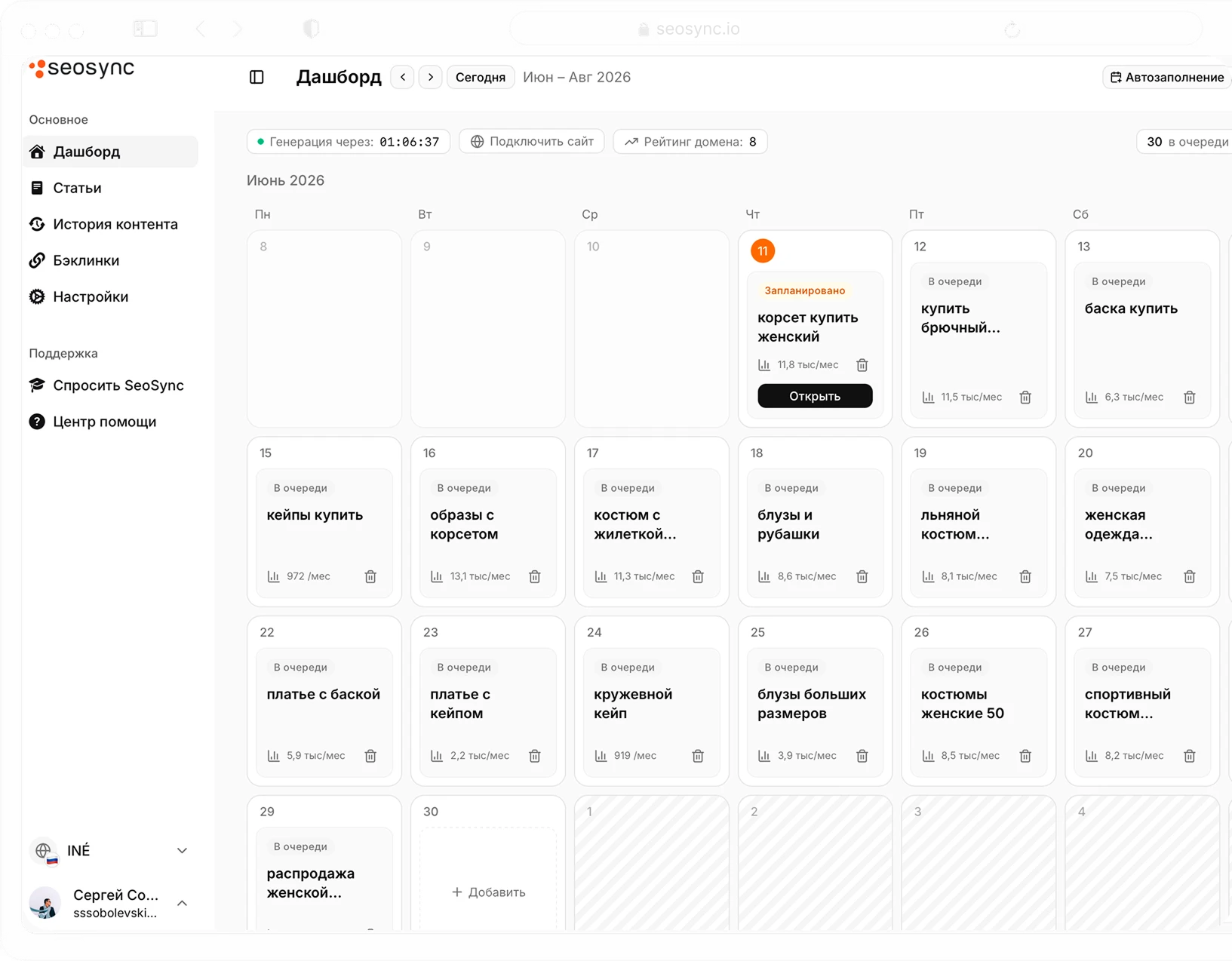

Трафик на автопилоте. Без агентств и рутины.
SeoSync возьмёт на себя рутину с контентом и SEO — вам остаётся развивать продукт и идеи.
Начать бесплатно